k8s的節點選擇與污染
前言
最近碰到的問題,起因是單台的對外連線數過大,導致程式發生問題,無法再連線到外部網路。
正文
在 GCP網路對外的方式裡面有提到,對外連線時,如果是私有叢集會使用Cloud NAT,
本次的情形,是因為再該節點內,某一個deploy疑似將連線數吃滿,最近想通了,應該是節點數量的問題。
nodeSelector
所以要將某一個服務,獨立掛在單一的節點池上面。
最簡單的用法是 nodeSelector,在 spec.template.spec 的下一層。
app : websocket 這個是label 在建立nodepool時,一併建立的。
也可在建立nodepool後,在手動新增label。當然也可以直接指定google賦予的label。
查詢label
kubectl get nodes --show-label
新增label
kubectl label node <node name> <label>=<value>
ref.
deploy的範例
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployabc
spec:
replicas: 10
template:
spec:
.......
nodeSelector:
app: websocket
ref.
將 Pod 部署到特定節點池
將 Pod 分配給節點
節點污點
剛上面有提到,deploy可以指定pod到特定的節點,但是當前面的節點滿了後,其他的deploy還是有可能會到特定的節點上。
k8s可以設定節點為 污點(Taint),使此污染的節點,只能接受有容忍度的pod。
污點的設定不能事後更新,所以要在一開始建立時就設定好。請注意(fig.2)的Taint。
另外建議統一由GKE的節點污點,從控制台建立或使用指令建立。
否則當node自動新增時,該節點並不會產生 Taits
設定時,要指定 key 與 value 以及 效果。
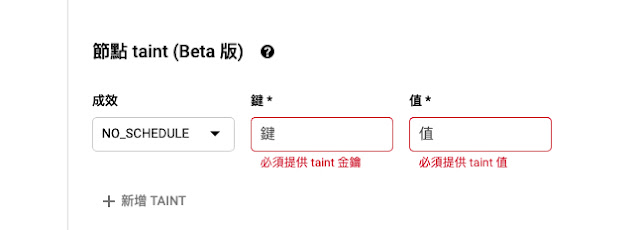
效果有以下三種:
- NoSchedule:不能容忍此污點的 Pod 不會被調度到節點上;現有 Pod 不會從節點中逐出。
- PreferNoSchedule:Kubernetes 會避免將不能容忍此污點的 Pod 安排到節點上。
- NoExecute:如果 Pod 已在節點上運行,則會將該 Pod 從節點中逐出;如果尚未在節點上運行,則不會將其安排到節點上。
ref.用節點污點控制調度
之後在deploy上面建立容忍(toleration)污點, 在 spec.template.spec 的下一層
其中 key 與 value 為自訂,效果請參考上面選擇。
apiVersion: apps/v1
kind: pod
metadata:
name: deployabc
spec:
replicas: 10
template:
spec:
container:
.......
tolerations:
- key: "visible"
operator: "Equal"
value: "private"
effect: "NoExecute"
tolerationSeconds: 3600
補充,如果是舊的節點集區,在GKE上面,可以改使用這個label去選擇。
cloud.google.com/gke-nodepool: <節點池的名稱>
tolerationSeconds不要亂設
當設定了以後,此pod就算符合條件,也會在特定時間內被驅逐後重建。
在GKE的版本 1.30.5-gke.1443001 ,針對了某個deploy增加此設定,
然後他會每個小時砍掉pod,重建一次,但還會在相同的node上面。
ref.
污點和容忍度
k8s進階篇(四):Affinity and Anti-Affinity、Taints and Tolerations